
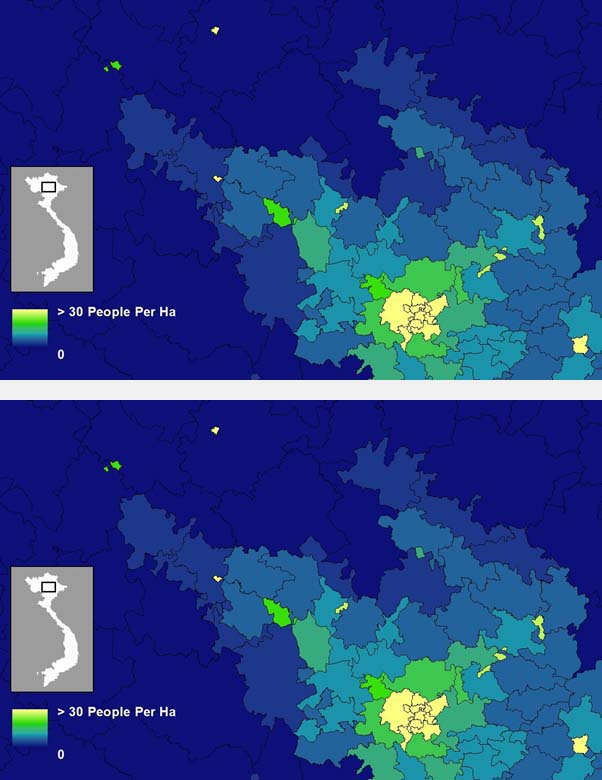
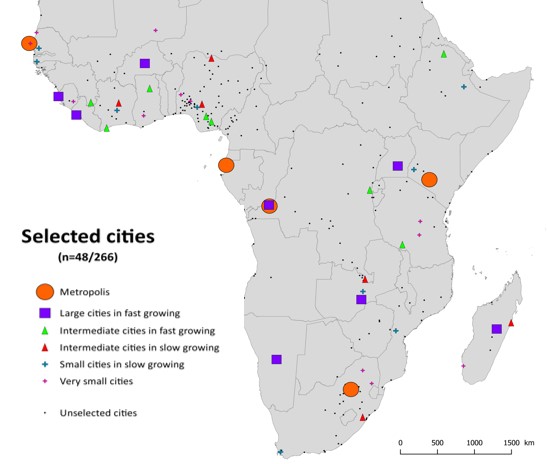
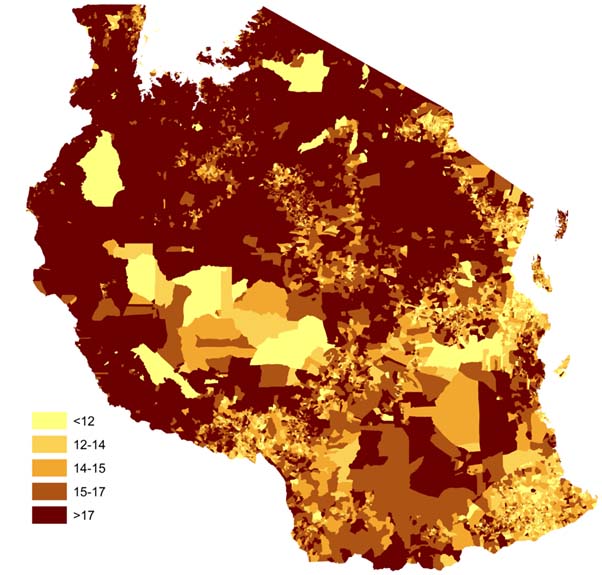
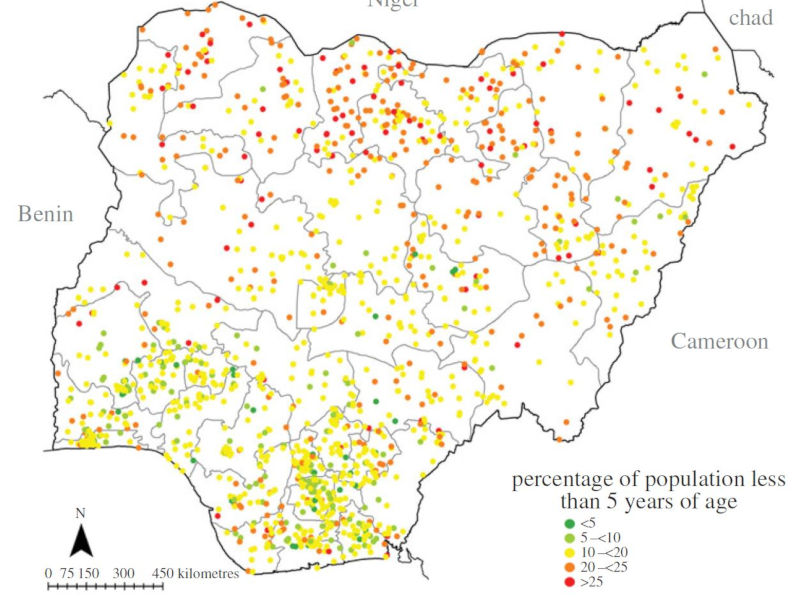
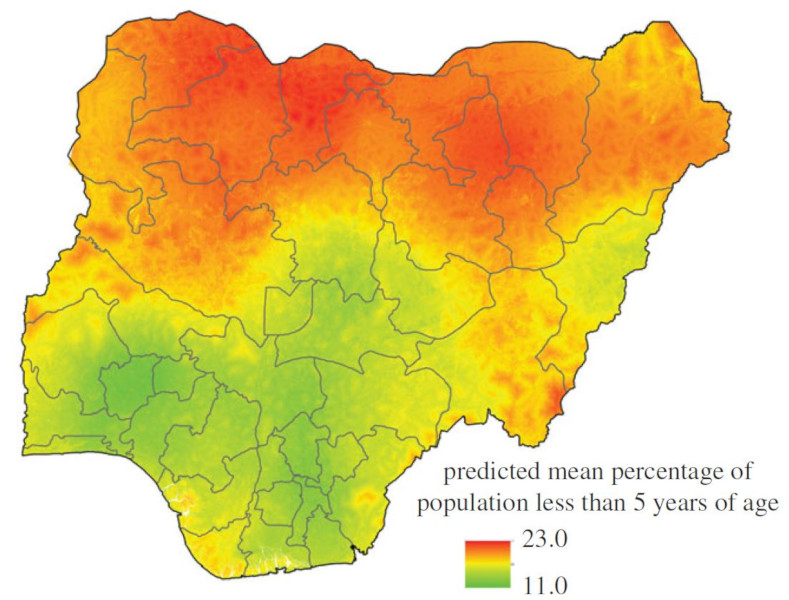
 Dynamic population mapping: Full details of the methods used to construct the datasets depicting monthly population densities per grid cell are available in Deville et al (2014) PNAS. In brief, mobile phone call data records were obtained for each country mapped and per cell tower call numbers were calculated for each month. These were converted to per grid cell call densities using Thiessen tessellations around cell towers and network coverage maps. Further, these were converted to estimates of population densities using empirical relationships between detailed census counts and call densities during the census taking period. This relationship enabled conversion of call densities into population density maps for time periods beyond the census count periods, facilitating the mapping of, for example, day/night, weekday/weekend, work/holiday difference population mapping. The video below illustrates this for France. Download Dynamic Mapping data (France and Portugal). Further datasets for low income nations will be made available soon.
Dynamic population mapping: Full details of the methods used to construct the datasets depicting monthly population densities per grid cell are available in Deville et al (2014) PNAS. In brief, mobile phone call data records were obtained for each country mapped and per cell tower call numbers were calculated for each month. These were converted to per grid cell call densities using Thiessen tessellations around cell towers and network coverage maps. Further, these were converted to estimates of population densities using empirical relationships between detailed census counts and call densities during the census taking period. This relationship enabled conversion of call densities into population density maps for time periods beyond the census count periods, facilitating the mapping of, for example, day/night, weekday/weekend, work/holiday difference population mapping. The video below illustrates this for France. Download Dynamic Mapping data (France and Portugal). Further datasets for low income nations will be made available soon.
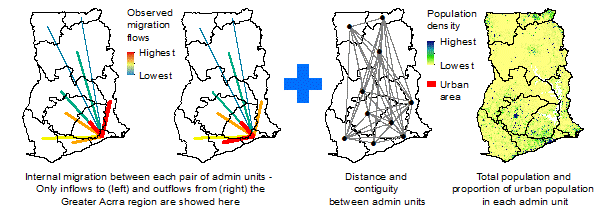
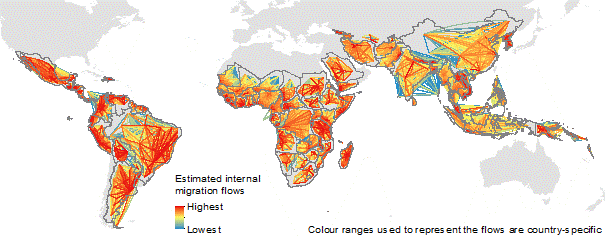
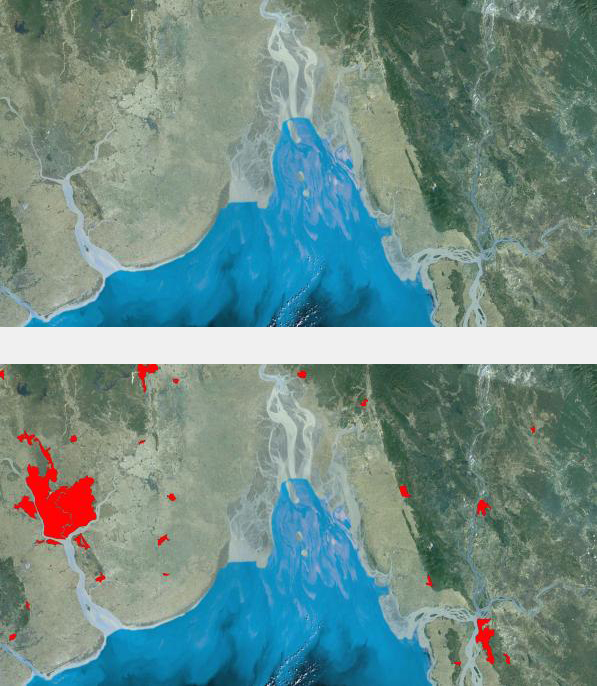
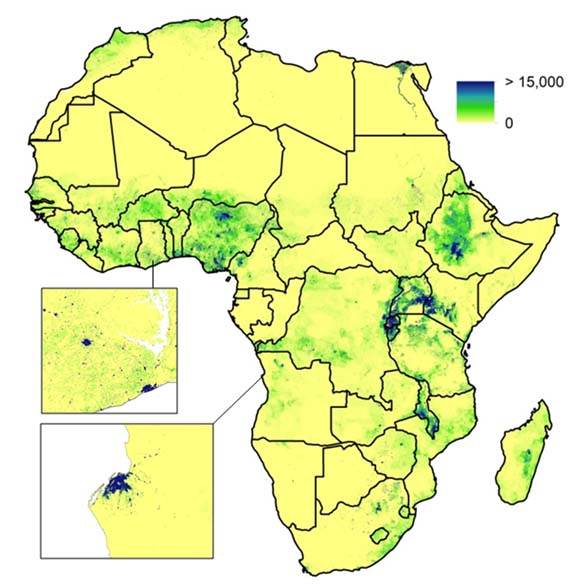
Mapping domestic population movements: In collaboration with the Flowminder Foundation, the mapping of population movements using mobile phone call data records (CDRs) is ongoing for many low and middle-income countries. These involve tracking de-identified communication patterns of individual SIM cards by phone tower to estimate population flows, displacements and commuting patterns. Full details can be found on the Flowminder website, and outputs for specific countries are made available on the World Events section of the WorldPop site.
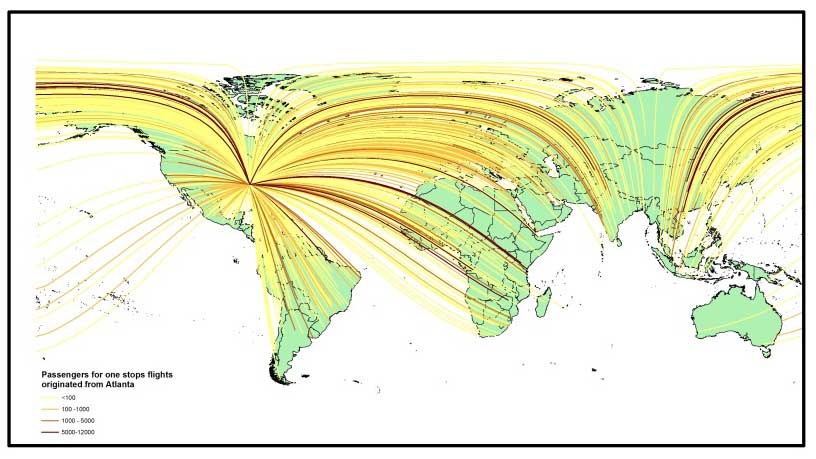
Mapping air passenger flows: Data on the numbers of people travelling via air travel between locations globally are generally difficult and expensive to obtain. Recent work described in Huang et al (2013) and Mao et al (2015) as part of the Vector-borne Disease Airport Importation Risk (VBD-Air) tool project has produced open access modelled passenger flow datasets, for both annual and monthly flows between airports globally. A set of Poisson regression models were built to predict monthly passenger volumes between directly and indirectly connected airports. The models not only performed well against ticketed data from the United States with an overall accuracy of 93%, but also showed good confidence in estimating air passenger volumes in other regions of the world. The image below shows an example of predicted flows of passengers from Atlanta making one stop on the way to their destination.